|
Tutorial zur Suche im WWWBernard Bekavac - Informationswissenschaft - Universität Konstanz bearbeitet von Lukas Müller, August 1999 |

|
Bernard
Bekavac - Informationswissenschaft - Universität Konstanz bearbeitet von
Lukas Müller, August
1999
Tutorial zur Suche
im WWW
1.1 Welche Informationsdienste sind über WWW erreichbar?
Viele Internetdienste, die schon lange vor dem WWW existieren und dem Benutzer verschiedene Arten von Informationen zur Verfügung stellen, sind heutzutage komfortabel über das WWW erreichbar. Die verbreitetsten und wichtigsten werden nachfolgend kurz erläutert: FTP, E-Mail, NewsGroups und natürlich das WWW selbst.
WWW
Durch seine grafische Aufbereitung
und durch die einfache Handhabung ist das WWW (World Wide Web) zum häufigst
genutzten Dienst im Internet geworden. Jeder, der eine grafische Oberfläche
bedienen kann, ist in der Lage, sich rund um die Uhr von Seite zu Seite zu hangeln
(zu "surfen"), Informationsserver anzusteuern, Zeitungsstände und Bibliotheken
zu befragen oder selbst eine globale, (fast) kostenlose Informationsseite anzubieten.
Dokumente sind im WWW in Form von Hypertext organisiert. Das bedeutet: sie enthalten
Verweise (sog. 'Links' oder 'Hyperlinks') auf andere Dokumente. Somit ist es
z.B. möglich, inhaltlich verwandte Themen miteinander zu verbinden, oder
ein 'assoziatives Lesen' zu ermöglichen. Ein Link bezieht sich nicht nur
auf Textdokumente, sondern auch auf eine Video- oder Audiosequenz, ein Bild,
auf andere Dienste wie z.B. E-Mail, News oder FTP.
FTP (File Transfer Protocol)
Fast alle Hard- und Software-Hersteller nutzen das Internet, um der Öffentlichkeit Zugriff auf ihre Softwarearchive zu geben. Damit sparen sie Geld, welches sie für den Disketten- bzw. CD-ROM-Versand per Briefpost ausgeben müßten. Das Internet ist schneller, billiger und inzwischen verbreitet genug. Das Spektrum der verfügbaren Dateien kann nur anhand einiger Beispiele angedeutet werden:
Zur Übertragung dieser
großen Datenmengen eignet sich besonders der Datei-Transfer-Dienst FTP,
der schon lange vor dem WWW existierte.
Der Zugriff auf FTP-Server verlangt normalerweise eine Benutzerkennung und zugehöriges
Paßwort. Bei den meisten FTP-Severn gibt es aber allgemein bekannte und
gültige Benutzerkennungen wie guest oder anonymous, weshalb
auch die Bezeichnung anonymous ftp verwendet wird. Beim Zugang zu FTP
über einen WWW-Browser wird die Benutzeranmeldung vom Browser automatisch
vorgenommen und das FTP-Dateiverzeichnis in WWW-Look angezeigt, so daß
der Benutzer meistens gar nicht bemerkt, daß mit einem anderem Dienst
als WWW gearbeitet wird.
Auch Software muß erst gefunden werden. Da FTP bereits sehr früh zu den Internetdiensten gehörte, wurde auch sehr früh der Ruf nach zentralen Softwarekatalogen laut. Weltweit gibt es sogenannte Archie-Server, die genau diese Funktion erfüllen. Die meisten Archie-Server sind inzwischen über WWW erreichbar, aber auch viele Suchdienste des WWW durchstöbern mittlerweile FTP-Server und bieten die Suche in diesen Softwarearchiven an.
E-Mail / Mailinglisten
Auf Briefköpfen und
Visitenkarten sieht man es immer öfter das Sonderzeichen @, auch "Klammeraffe"
genannt. Dieses Zeichen steht für das englische "at" und steht bei den
meisten E-Mail-Adressen hinter dem Namen des Benutzers und vor dem Rechnernamen
des elektronischen Briefkastens.
Wer eine E-Mail-Adresse besitzt, ist nicht nur von jedem Computer der Welt aus
, auch off-line, erreichbar, er selbst kann von jedem Computer der Welt aus
seinen Briefkasten kontrollieren und entleeren. E-Mail bietet neben einer schnellen
und direkten Kontaktaufnahme mit Personen in der ganzen Welt auch die Möglichkeit
z.B.:
Ein weiterer Vorteil von E-Mail ist der "File-Attach", das Mitsenden digitaler Daten. Formatierte Winword-Texte, farbige Grafiken, eingescannte Fotos, Videoclips und Sounddateien können per E-Mail versendet werden.
Um über E-Mail kommunizieren
zu können, muß natürlich die E-Mail-Adresse des Kommunikationspartners
bekannt sein. Ist dies nicht der Fall, so ist die Suche nach der richtigen E-Mail-Adresse
nicht einfach, denn im Gegensatz zu den anderen Diensten ist das Sammeln von
E-Mail-Adressen durch einen Suchdienst gar nicht bzw. nur eingeschränkt
automatisierbar.
Deshalb werden im WWW immer größer werdende E-Mail-Kataloge mit Zusatzinformationen
zu den jeweiligen E-Mail-Adressen von den Internet-Benutzern aufgebaut und gepflegt.
Newsgroups / FAQ
Bei Newsgroups handelt es
sich um ein System von öffentlichen Schwarzen Brettern, die nach Themen
bzw. Foren unterteilt sind und in ihrer Gesamtheit fast jedes denkbare Thema
abdecken. Beim Gedankenaustausch der Teilnehmer werden insbesondere aktuelle
Ereignisse diskutiert oder angekündigt.
Hervorgegangen ist das System aus den sogenannten Usenet News , die sich zunächst
unabhängig vom Internet entwickelt haben. Es war ein System von mehreren
tausend Rechnern weltweit, die die Beiträge der Teilnehmer zu den einzelnen
Diskussionsforen untereinander austauschten. Heute wird zwar der größte
Teil des Datentransfers über das Internet abgewickelt.
Um die riesige Menge an Foren übersichtlich zu strukturieren, sind die einzelnen Gruppen in hierarchische Kategorien aufgeteilt, was sich an ihren Namen ablesen läßt.
alt alternative - Mischung aus allen Themen, die nicht in eine der anderen Gruppen einzuordnen sind biz business - Kommerzielle Themen comp Computer-Themen (Software und Hardware) misc miscellaneous - Verschiedene Themen, die sonst keine eigenen Foren haben news Themen rund um das Newssystem selber rec recreational - Hobby und Freizeit sci scientific - wissenschaftliche Themen soc social - soziale und kulturelle Foren aus vielen Ländern der Welt
Es gibt noch eine Vielzahl weiterer Kategorien - die Namen sind meist selbsterklärend. Für deutsche Benutzer ist jedoch vor allem die .de-Kategorie interessant:
de deutschsprachige Gruppen. .de wird den oben genannten Kategorien vorangestellt (z.B. de.sci.chemie)
Einige Newsgroups werden von WWW-Suchdiensten abonniert und somit sind deren aktuelle Artikel bei der Suche nachweisbar.
In vielen Newsgroups gibt es eine sogenannte FAQ-Datei (Frequently Asked Questions). Diese Dateien beinhalten eine Sammlung der häufigsten Fragen und zugehörigen Antworten, die in der jeweiligen Gruppe gestellt wurden. Bevor ein Benutzer eine Frage an eine Newsgroup stellt, soll dieser die Möglichkeit haben, die häufigsten Fragen vorab in der FAQ-Datei zu lesen, damit die regelmäßigen Leser einer Gruppe nicht immer wieder mit den gleichen Fragen konfrontiert werden. Der Standort der FAQ-Dateien wird in regelmäßigen Abständen in der Gruppe veröffentlicht. FAQ-Dokumente sind im Internet aber auch zu vielen anderen Themen verfügbar, unabhängig von entsprechenden Newsgroups. Sie werden auf FTP-Servern, aber auch immer öfter über WWW zugänglich gemacht und sind somit über verschiedene WWW-Suchdienste auffindbar.
1.2 Wer sind die Informationsanbieter?
Privatpersonen
Es werden eine Vielzahl von Privaten Home-Pages der Internetbenutzer angeboten. Diese enthalten meist Angaben zur Person, Adresse, E-Mail und sonstige Informationen. Zusätzlich werden auf Home-Pages auch mehr oder weniger umfangreiche Verweise und Informationssammlungen zu eigenen Interessensgebieten angeboten. Home-Pages sind oft in privaten Unterverzeichnissen von WWW-Servern zu finden und über ein Sonderzeichen "~" (Tilde) in der URL direkt ansprechbar und somit leicht zu erkennen.
Bsp.: "http://www.inf-wiss.uni-konstanz.de/~mustermann/"
Kommerzielle Organisationen / Firmen
Firmen aller Größen
und Sparten präsentieren sich und ihre Produkte auf WWW-Seiten. Dabei gehen
immer mehr Unternehmen dazu über, auch Anwendungen über Internet anzubieten.
D.h. es können über Internet Bestellungen absolviert, Geschäfte
transparent gemacht oder wie im Falle von einigen Direktbanken auch die komplette
Kontoführung übernommen werden. Ein 24-Stunden-Service versteht sich
dabei von selbst.
Die meisten Unternehmen haben eigene Server bzw. Domain-Namen und sind oft an
diesem erkennbar.
Bsp: "http://www.ibm.com/", "http://www.microsoft.de/"
Universitäten, Institute und sonstige Forschungseinrichtungen
Über die WWW-Seiten
von Universitäten stehen recht unfangreiche Informationen zu Studiengängen,
Fakultäten, Forschungsprojekten und sonstigen für das Studium wichtigen
Informationen bereit. Immer mehr wissenschaftliche Einrichtungen gehen dazu
über, WWW-Bereiche und E-Mail-Accounts sowohl allen Mitarbeitern als auch
Studenten kostenlos zur Verfügung zu stellen. Wissenschaftliche Publikationen,
Berichte und Ergebnisse werden immer mehr auch von nicht-informatikbezogenen
Bereichen über WWW zugänglich gemacht. Traditionell beinhalten FTP-Server
von Universitäten eine große Anzahl an Public-Domain Software.
Deutsche Universitätsserver beinhalten meistens Universitätskürzel
(uni, fu, tu, fh), amerikanische ".edu" in ihren Domain-Namen.
Bsp: "http://www.uni-konstanz.de/",
"http://www.tu-berlin.de/",
"http://www.berkeley.edu/"
Nicht-kommerzielle Organisationen
Politische Parteien und
Regierungen, Umwelt- und Menschenrechtsorganisationen wie z.B. Greenpeace oder
Amnesty International, diverse kirchliche Organisationen, Interessens- und Sportverbände
bis hin zu kleinen Freizeitvereinen bieten ihre offiziellen Informationen über
WWW an.
Dabei liegt das Informationsangebot von auf mehreren WWW-Servern, bei größeren
Organisationen, bis in einfachen Home-Pages bei kleineren Interessensgebieten
verteilt.
Bsp: "http://www.bundesregierung.de/", "http://www.greenpeace.org/", "http://www.amnesty.org/"
Medienanbieter und Anbieter kommerzieller Datenbanken
Traditionelle Vermittler von gedruckter und nicht-gedruckter Information wie Zeitungen, Verlage, Agenturen, Buchhandlungen, Radio- und Fernsehsender bieten ihre Produkte in bereits professionellem Design über das WWW an. Dabei wird oft auch die Möglichkeit gegeben, in Archiven zu stöbern, was früher nur bestimmten Personen möglich oder ansonsten recht schwierig war.
Datenbankanbieter, sogenannte
Hosts, bieten schon seit längerem die Recherche in Tausenden von elektronischen
Datenbanken aus allen Bereichen, mit bibliographischen Angaben (Autor, Titel,
Thema, Verlag...) oder Volltext, online an. Auch hier war früher die Recherche
wegen den technischen Zugangsmöglichkeiten, vor allem aber wegen den recht
komplexen und unterschiedlichen Retrievalsprachen eher den professionellen Informationsvermittlern
überlassen.
Über WWW-Seiten kann nun in den Datenbanken über komfortable Formulare
direkt recherchiert werden. Anmeldung und Kosten für die Recherche in kommerziellen
Datenbanken entfallen jedoch nicht.
Bsp: "http://www.ard.de/", "http://www.buchkatalog.de/", "http://www.fiz-karlsruhe.de", "http://www.genios.de"
Bibliotheken
Auch Bibliotheken bieten
ihre Literaturkataloge seit einigen Jahren und schon vor dem WWW online an -
die sogenannten OPACs (Online Public Access Catalogs). Aber auch hier gab es
Hürden, wie z.B. verschiedene Retrievalsprachen und Benutzeroberflächen.
Die einzelnen OPACs beinhalten auch jeweils nur den Bestand einer Bibliothek.
Der Gang der Bibliotheken an das WWW brachte nicht nur komfortablere und einfachere
Oberflächen mit sich, sondern auch Verbunde mehrerer OPACs und die gleichzeitige
Suche in diesen.
Bsp.: "http://www.bib-bvb.de/" - Bibliotheksverbund Bayern
Über WWW sind die wichtigsten, oben beschriebenen, Internet-Dienste erreichbar. Dank vieler und verschiedenartiger Suchdienste, Gateways und vor allem auch der schier unendlichen Fülle von individuellen Tips, Hinweisen und Nachweisen auf persönlichen und institutionellen WWW-Seiten kann man davon ausgehen, daß sich der überwiegende Teil von Internet-Ressourcen über das WWW aufspüren läßt. So sind die nachfolgend beschriebenen Suchverfahren auf das WWW eingeschränkt, zumal traditionelle Internet-Suchverfahren sich immer mehr auf das WWW konzentrieren und daher in ihrer ursprünglichen Form immer mehr an Brauchbarkeit und Bedeutung verlieren.
2.1 Suche in lokalen WWW-Servern / Gateways zu Datenbanken
Die lokale Suche innerhalb eines WWW-Servers war eine der ersten Möglichkeiten, dem Benutzer die Suche nach relevanten Informationen im WWW zu ermöglichen. Dabei handelt es sich um eine einfache Stichwortsuche, die auf das Dokumentverzeichnis des lokalen WWW-Servers zugreift. Dieses einfache Suchverfahren war schon von den WWW-Entwicklern am CERN durch die Dokumentbeschreibungssprache HTML und das WWW-Übertragungsprotokoll HTTP vorgegeben. Das HTML-Element <ISINDEX> kennzeichnet dabei eine Suchmöglichkeit innerhalb des jeweiligen Dokuments. Es ist dann die Aufgabe des WWW-Browsers, innerhalb dieser WWW-Seite ein Eingabefeld für Suchbegriffe anzubieten. Die dort eingegebenen Suchbegriffe werden dann nach HTTP-Protokollspezifikation mit einem vorangehenden ,,?" und durch ein ,,+" voneinander getrennt an die Dokumentadresse angehängt. Wurden z.B. Hypertext und Information als Suchbegriffe eingegeben, so hängt der WWW-Client diese Suchbegriffe in seinem Request an die Dokumentadresse an: ,,http://host/suche?hypertext+information". Darauf sucht der WWW-Server in all seinen Dokumenten nach diesen Suchbegriffen und liefert eine Liste mit Verweisen, deren Dokumente die Suchbegriffe beinhalten, an den Client zurück.
Diese Suchmöglichkeit
war in den Anfängen des WWW sicherlich ausreichend. Heutzutage beinhalten
schon viele WWW-Server so eine große Anzahl an Dokumenten, daß eine
einfache Stichwortsuche nur unbefriedigende Ergebnisse erzielt. Eine diesbezügliche
Erweiterung von HTML und HTTP steht vorerst nicht zur Diskussion, so mußte
man andere Wege zu besseren Suchverfahren finden.
Sollte die Suche also nicht nur auf Volltextsuche und einfache Suchoperatoren
beschränkt sein, sondern auch Dokumentstruktur, bestimmte Felder (URL,
TITLE...), Relevanzgrade usw. in die Suche miteinbezogen werden, so müssen
zusätzliche Software-Komponenten in Verbindung mit Datenbanken auf der
Server-Seite die Anfrageabarbeitung erledigen. Zum Zweck der Weitergabe von
WWW-Requests an Programme auf dem Server gibt es die CGI-Schnittstelle (Common
Gateway Interface). Dokumente, die Programme über CGI aktivieren und dem
Benutzer einen bestimmten Dienst ermöglichen, werden auch als Gateway bezeichnet.
Dabei werden Daten über HTML-Formulare in verschiedenen Eingabefeldern
eingegeben und die Eingaben auf Server-Seite an Hintergrundprogramme über
CGI weitergeleitet. Wird dieses Verfahren für die Suche nach WWW-Dokumenten
verwendet, so können fast uneingeschränkt Suchhilfen über CGI-Programme
implementiert und genutzt werden. Eine große Anzahl von WWW-Servern bieten
inzwischen solch ein Gateway an, um dem Nutzer eine professionelle Suche nach
lokalen Dokumenten zu ermöglichen.
Im Hinblick auf Information Retrieval allgemein werden über WWW-Gateways die Suchmöglichkeiten nicht alleine auf WWW-Dokumente beschränkt, gibt es schon viele Datenbankanbieter und Produzenten, die komfortable WWW-Schnittstellen zu ihren Datenbanken bieten. Das gleiche gilt für die Suche nach Literatur in Bibliotheken. Dabei wird ein Zugang zu verschiedenen Bibliotheksdatenbanken mit diversen literaturüblichen Suchfeldern (Autor, Verlag...) ermöglicht.
2.2 Katalog- und verzeichnisbasierte Suche
Zusammenstellungen von Verweisen zu bestimmten Sachgebieten kennzeichneten den Beginn der globalen Suche im WWW. Die Entwickler des WWW bauten solch eine Zusammenstellung aus, um das WWW zu verbreiten, aber auch um diese Verbreitung mitzuverfolgen. Daraus entstand einer der umfangreichsten WWW-Kataloge, die WWW Virtual Library, die inzwischen auf mehrere Institutionen weltweit verteilt ist. Parallel dazu entstanden auch andere Kataloge großen Umfangs und dienten »lange« Zeit der WWW-Welt als beste globale Suchmöglichkeit.
Das Suchverfahren in Katalogen basiert auf der Navigation in hierarchisch aufgebauten Sachgebieten oder geographischen Listen bzw. Karten. Dadurch, daß nicht zu viele Dokumente auf einer Ebene sein dürfen, da sonst der Benutzer schnell das Interesse durch ein informationelles Überangebot verlieren könnte, sind die Organisatoren von Katalogen gezwungen, nach »guten« Startseiten (Home Pages) zu den einzelnen Themen zu suchen. So werden nur bekannte und themenrelevante WWW-Dokumente aufgenommen. Auf den Inhalt eines Katalogs kann man aber auch selbst Einfluß nehmen, indem über WWW-Formulare Verweise auf eigene Dokumente eingetragen oder Vorschläge gemacht werden können. Fast jeder Katalog bietet eine Rubrik »Home Pages« für Privatpersonen an, in dem beliebige Dokumentverweise erlaubt sind. In beiden Fällen erfolgen die Einträge manuell und die Aktualität sowie richtige Einordnung der Einträge hängt von den Eintragenden ab.
Kataloge eignen sich vor allem, wenn man zu einem gewissen Thema bzw. Sachgebiet einen Einstieg finden will ohne dabei ganz gezielt nach bestimmter Information zu suchen. Das Browsen des Benutzers in einem Katalog erlaubt auch Einblicke in ähnliche und benachbarte Themen (Serendipity), die beim Einstieg in neue Gebiete durchaus wünschenswert sind und bei der Stichwortsuche eher ausbleiben.
Aber auch WWW-Kataloge sind so umfangreich, daß die Navigation in diesen schwerfällig ist und Möglichkeiten zur schnellen Suche über Stichworte und Suchhilfen angeboten werden. Diese Stichwortsuche ist aber für den Benutzer meist sehr unzufriedenstellend, da die Suche nicht auf den Volltexten basiert, sondern nur über Inhalte des Titels und der Dokumentadresse gesucht wird. Die angebotenen Suchmethoden und -operatoren sind deshalb meist nur auf Boolesche Operatoren und eine Suchraumeingrenzung auf die einzelnen Katalogrubriken beschränkt.
Jedoch gibt es auch Kataloganwendungen, bei denen die Stichwortsuche eine größere Rolle spielt als die Navigation, wie z.B. bei E-Mail-Adressverzeichnissen. Abgesehen davon, daß die globale Suche hierbei nur über WWW-Kataloge bzw. Verzeichnisse möglich ist, da E-Mail-Adressen im Gegensatz zu Web-Seiten nicht automatisch abgefragt werden können, ist der Anwender weniger daran interessiert, in einem E-Mail-Verzeichnis zu navigieren, sondern eher über die Stichwortsuche die gewünschte E-Mail-Adresse herauszufinden.
2.3 Roboterbasierte Suche / Suchmaschinen
Roboter, auch Spider, Wanderer oder Worm genannt, sind Programme, die entlang von WWW-Hypertextstrukturen Dokumente automatisch verarbeiten. Dabei wird ein Dokument geladen, der Inhalt analysiert und es werden referenzierte Dokumente rekursiv weiterverfolgt. Einige große Suchdienste haben über ihre Roboter schon große Teile des Webs abgearbeitet. Die zugehörigen Volltextindizes oder auch nur Teilindizes der Dokumente wurden in Datenbanken gespeichert. Diese Datenbanken bilden die Grundlage für die Suchmaschinen bzw. Such-Server, die inzwischen über Benutzerschnittstellen mit diversen Abfrageformularen die Suche nach WWW-Dokumenten ermöglichen.
Die Vorteile dieses Suchverfahrens liegen auf der Hand. Über Abfrageformulare, über die die meisten Suchmethoden und -operatoren angewendet werden können, kann der Benutzer weltweit nach Informationen suchen. Die Suchanfrage wird in einer üblicherweise angemessenen Zeit vom Suchserver abgearbeitet und das Ergebnis dem Benutzer in Form einer meist nach Relevanzgrad sortierten Trefferliste präsentiert. Teilweise werden zu den Treffern auch Teile des Originaldokuments oder automatisch generierte Abstracts sowie andere Zusatzinformationen hinzugefügt, die dem Benutzer helfen sollen, die Relevanzbestimmung zu erleichtern. Dieser kann dann direkt zu den Trefferdokumenten navigieren und von dort aus, falls nötig, über weitere Navigation die gewünschte Information erarbeiten. Die semantische Zusammengehörigkeit von WWW-Hypertexten oder die hierarchische Struktur, die WWW-Kataloge wenigstens ansatzweise wiedergeben, lassen roboterbasierte Suchdienste allerdings ganz außer acht.
Die ständigen Zugriffe der Suchmaschinen belasten natürlich auch weltweite WWW-Server. Die Belastung von WWW-Server durch Roboter hängt zum einem von der Anzahl Roboter und ihrer Zugriffshäufigkeit ab und zum anderem von der Strategie des Zugriffs. Dabei wird unterschieden, ob parallel auf mehrere Dokumente zugegriffen wird oder ob die WWW-Seiten sukzessive abgerufen werden. Tests haben ergeben, daß sich sowohl die eine oder andere Zugriffsstrategie bei WWW-Servern negativ auf die Performance auswirken kann. Natürlich spielen dabei auch weitere Faktoren eine Rolle, wie z.B. die Leistungsfähigkeit einer Server-Maschine und ob diese zusätzlich anderweitig genutzt wird. Immerhin gibt es die Möglichkeit, über den »Standard for Robot Exclusion« WWW-Server vor Roboterzugriffen zu schützen. Im Prinzip ist dies eine spezielle Datei im Serververzeichnis, über die Roboter erfahren, welche Dokumente bzw. Teile des Servers gelesen werden dürfen. Dies ist jedoch kein richtiger Zugriffsschutz, sondern eine Art Abmachung unter den Betreibern der Suchdienste.
Die Bekanntheit und Beliebtheit
von Suchservern spiegelt sich in ihrem Zugriff wieder: Die bekanntesten Suchmaschinen
bearbeiten bis zu 15 Millionen Anfragen pro Tag.
Die Verarbeitung und Aktualisierung einer stark wachsenden Anzahl von WWW-Dokumenten
weltweit sowie die große Menge von Suchanfragen verlangen die höchsten
Ansprüche an Hard- und Software des Suchservers. Meistens sind die Aufgaben
in solch einem System auf mehrere in einem Netz verbundene Rechner verteilt.
Dabei werden unterschiedliche Softwarekomponenten eingesetzt. Welche Programme
dies konkret sind, ist von Dienst zu Dienst unterschiedlich. Als Hauptkomponenten
kann man aber auf jeden Fall Roboter, Datenbank und die Anfragebearbeitung herausstellen.
Die Suchmaschinen sind zweifellos die weitaus meistbenutzten und komfortabelsten Suchdienste des Internet. Um diese richtig einzusetzen und damit einen hohen Nutzen daraus zu ziehen, bedarf es neben der Kenntnis und Anwendung der weiter unten beschriebenen Suchmethoden und -operatoren auch eines tieferen Einblickes in ihre Funktionsweisen. Dies ist vor allem wichtig, um sich bewußt zu machen, welche Internet-Dokumente nun tatsächlich von den Robotern erschlossen werden und welche nicht.
2.3.1 Funktionsweise von Suchmaschinen
Der technische Aufbau einer Suchmaschine soll hier beispielhaft anhand des Suchdienstes WebCrawler demonstriert werden:
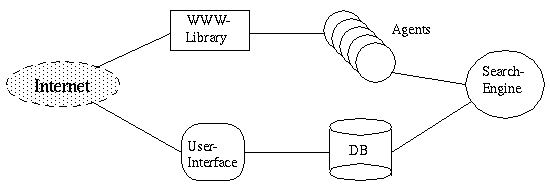
Systemaufbau der Suchmaschine WebCrawler
Die Suchmaschine betrachtet
das Web als riesigen gerichteten Graphen, wobei Knoten WWW-Dokumente und gerichtete
Kanten die Verweise darstellen, die von einem Dokument ausgehen. Von einem bestimmten
Knoten aus wird dann der Graph entlang den Kanten abgearbeitet.
Bei jedem so erreichten Dokument wird von der Suchmaschine eine lexikalische
Analyse durchgeführt, bei der inhaltsrelevante Terme aus dem Dokument extrahiert
und in der Datenbank (DB) abgelegt werden. Das Abrufen der WWW-Dokumente erledigen
parallel laufende Agenten-Prozesse. Diese geben der Suchmaschine entweder das
gewünschte HTML-Dokument oder eine entsprechende Fehlermeldung, warum auf
das gewünschte WWW-Dokument nicht zugegriffen werden konnte. Ferner nutzen
die Agenten den Katalog WWW Virtual Library für die Dokumentbesorgung.
Der Benutzer greift auf das System über den Suchserver (User-Interface)
zu, der zwecks Anfragebearbeitung auf die von der Suchmaschine aufgebaute Datenbank
zugreift.
Die Aufgaben einer Suchmaschine lassen sich grob in vier Teilaufgaben zerlegen: Akquisition, Indizierung, Aktualisierung und die Anfragebearbeitung. Im folgenden werden diese vier Teilaufgaben genauer beschrieben.
Um zu wissen, welche Internet-Dokumente von den Suchrobotern erreicht werden, ist es wichtig, die Akquisition der Dokumente näher zu betrachten.
Woher bekommen Suchmaschinen die Adressen der zu holenden Dokumente?
Vom Benutzer (Add/Submit
URL)
Ansonsten ist bei den Suchdiensten ein manueller Eintrag über die Add/Submit
URL-Seiten der Suchmaschinen notwendig. Dabei können oft
auch zusätzliche Informationen (Autor, Kommentare, E-Mail-Adresse usw.)
angegeben werden.
Rekursives Folgen
von WWW-Hypertextlinks
Über Kataloge und Benutzereintragungen werden Roboter auf Dokumente
"aufmerksam" gemacht, von denen aus dann die Links automatisch weiterverfolgt
und in regelmäßigen Abständen aktualisiert werden. Die Tiefe
der rekursiven Verfolgung der Links ist von Suchmaschine zu Suchmaschine
unterschiedlich. Im Schnitt wird ca. drei Ebenen tief weiterverfolgt.
Welche Dienste können von Suchmaschinen erreicht werden?
News-Groups
Einige Suchmaschinen "abonnieren" selbst die wichtigsten und populärsten
NewsGroups und ermöglichen die Suche in den aktuellen Postings. Es
gibt aber auch schon spezialisierte Suchmaschinen, die nur NewsGroups beinhalten.
Die Anzahl Foren und die zeitliche Abdeckung ist bei diesen natürlich
weitaus größer.
FAQ-Dateien werden ebenfalls über WWW oder FTP indiziert.
FTP-Daten
Immer mehr Suchmaschinen analysieren auch FTP-Verzeichnisse. Die Suche in
diesen ist meist auf Pfadnamen und Textdateien eingeschränkt.
Welche Problembereiche gibt es bei den erreichbaren Diensten?
FTP-Daten
News-Groups
Welche Bereiche werden von Suchmaschinen nicht erreicht?
E-Mail
E-Mail-Adressen können nicht automatisch akquiriert werden
Dateien (Außerhalb
des WWW-Server-Bereiches)
Dateien, die über WWW-Browser mit »file:« erreichbar
sind, können von den Suchmaschinen nicht erreicht werden
Das Angebot von Suchmethoden und -operatoren ist in erster Linie von der Indizierung und der daraus resultierenden Datenbank abhängig. Dabei sind sowohl Analysemethoden als auch der Umfang der Indizierung der einzelnen WWW-Seiten von großer Bedeutung. Zur Dokumentanalyse werden von den verschiedenen Suchmaschinen diverse Methoden eingesetzt:
Auch im Umfang werden verschiedene Strategien verfolgt
Einige Suchmaschinen erlauben auch das Abfragen und Löschen der Datenbankeinträge eigener URLs.
Technisch gesehen ist beim Übertragen einer WWW-Seite ein für die Aktualisierung wichtiger Mechanismus im WWW-Protokoll vorhanden:
Bei der Aktualisierungsfrequentierung gibt es große Unterschiede in Art und Zeit bei den Suchmaschinen:
Nicht zugreifbare Dokumente, d.h. Seiten, die nach mehrmaligen Zugriffsversuchen nicht zugreifbar waren, werden von den meisten Suchmaschinen wieder gelöscht.
Das Angebot an Funktionalität
bei der Anfragebearbeitung ist natürlich abhängig von der Erschließung
der Dokumente. Je besser die Analyse und Indizierung der Dokumente ist, desto
umfangreicher ist das Angebot an Suchmethoden und -operatoren.
Die Benutzerschnittstelle ist nach der Funktionalität ausgerichtet und
bei den meisten Suchmaschinen über verschiedene Stufen komfortabel bedienbar:
Für die Relevanzbeurteilung (Ranking) und die damit verbundene Sortierung der Treffermenge werden fast nur statistische Methoden verwendet:
Immer mehr Suchmaschinen gehen aber auch dazu über, die Popularität eines Dokuments beim Ranking zu bewerten. Je öfter ein Dokument über eine Suchmaschine nachgewiesen wird, desto höher wird dieses im Rankingverfahren bewertet.
Manche Suchmaschinen erlauben aber auch die Sortierung der Trefferliste nach anderen Kriterien wie Größe, Alter oder nach Servern. Die Sortierung nach Servern (Excite) bietet eine leichte Verbesserung der Relevanzbeurteilung für den Benutzer, da sich auf einem Server meist gleichartige Dokumente befinden. So genügt es oft, nur noch ein Dokument pro Server zu betrachten.
2.3.2 Tips für die Erstellung eigener WWW-Seiten
Um nicht nur professionell
nach relevanten Informationen im WWW suchen zu können, sondern damit auch
die eigenen WWW-Dokumente von anderen bei entsprechenden Suchbegriffen gefunden
werden, werden nachfolgend einige Tips für die Erstellung von WWW-Seiten
aufgeführt.
Vornweg soll aber darauf hingewiesen werden, daß die vielfache Wiederholung
von Begriffen im TITLE- / META-Element (oder sonstigen Bereichen einer WWW-Seite,
die vom Browser nicht angezeigt wird), auch »spamming« genannt, für
die stärkere Gewichtung der Begriffe bei der Suche nichts (mehr) einbringt.
Im Gegenteil! Viele bekannte Suchmaschinen sind inzwischen dazu übergegangen,
solche Seiten nicht mehr in ihre Datenbanken zu speichern.
Tips für die Erstellung von WWW-Seiten:
Der Begriff »Hybride Suchmaschinen« etabliert sich immer mehr für Suchdienste, die mehrere Suchverfahren vereinen. Dabei wird meist der (roboterbasierte) Suchraum mit einen Katalog kombiniert und die Suche durch Gateways zu anderen Informationsquellen erweitert:
2.5 Metasuchmaschinen (Multi-Search Engines)
Als Metasuchmaschine wird
die Suche in mehreren Suchmaschinen, von einer WWW-Seite aus, bezeichnet. Wichtig
dabei ist, daß die Suchmaschinen nur über ein einziges Suchformular
angesprochen werden.
Fälschlicherweise werden aber auch WWW-Seiten mit einfachen Schnittstellen,
d.h. mehrere Suchmasken verschiedener Suchmaschinen, als Metasuchmaschinen bezeichnet.
Dies sind zwar keine »echten« Metasuchmaschinen, bringen aber trotzdem
gewisse Vorteile:
Echte Metasuchmaschinen weisen folgende Charakteristiken auf:
Dabei werden zwei grundlegende Techniken unterschieden: Der sequentielle und der parallele (gleichzeitige) Zugriff auf mehrere Suchmaschinen:
Sequentielle Suche in mehreren Suchmaschinen
Parallele Suche in mehreren Suchmaschinen
Metasuchmaschinen eignen sich vor allem bei ganz speziellen Informationsproblemen, bei denen einzelne Suchmaschinen nur wenige Treffer aufweisen. Metasuchmaschinen sind aber auch meistens auf dem neuesten Stand und beinhalten ganz neue Suchmaschinen oder ganz spezielle Datenbanken, die man selbst sonst noch gar nicht kennt.
2.6 Intelligente / Mobile Agenten
Mit dem Fortschreiten der
weltweiten Vernetzung und der damit verbundenen steigenden Komplexität
bedarf es neben den teilweise schon ausgereiften Suchdiensten auch der Erforschung
und Entwicklung neuer Methoden zur Unterstützung der Nutzer für ein
effizientes und zielgerichtetes Arbeiten im Internet.
In diesem Zusammenhang hört man oft den Begriff »Intelligente«
oder »Mobile« Agenten. Diese weiterführenden Konzepte aus dem
Bereich der Künstlichen Intelligenz versprechen eine weitere Professionalisierung
des Umgangs mit dem Internet. Die aufgrund dieser Konzepte entwickelten intelligenten
Agenten sind Programme, die Aufträge eines Benutzers oder eines anderen
Programmes mit einem gewissen Grad an Eigenständigkeit und Unabhängigkeit
ausführen und dabei Wissen über die Ziele und Wünsche des Benutzers
anwenden.
Wenn auch momentan keine universell gültige und akzeptierte Definition
des Begriffs »Agenten« existiert, gibt es doch einige Charakteristiken,
die solche Agenten gemeinsam haben (sollten):
Als »Mobile Agenten« werden solche bezeichnet, die sich selbst mitsamt ihrem Code und ihrem inneren Zustand, d.h. mit den bis dahin von ihnen gesammelten Informationen, durch das Internet bewegen können. Die hier besprochenen Charakteristiken sind nicht notwendig mobil. Nicht alle mobilen Agenten benutzen Mittel der Künstlichen Intelligenz.
Beim heutigen Stand der
Technik ist man bei der Realisierung der meisten hier genannten Eigenschaften
intelligenter Agenten jedoch noch weit entfernt. Einige der Eigenschaften werden
möglicherweise auch immer eine Utopie bleiben.
Der momentane Stand der Agententechnologie soll deshalb an zwei Beispielen existierender
WWW-Agenten gezeigt werden:
Webhound (http://webhound.www.media.mit.edu/projects/webhound/)
Das am Media Lab des Massachusetts Institute of Technology entwickelte Projekt
»Webhound«, auch Webdoggie genannt, stellt dem WWW-User einen persönlichen
Document Filtering-Agent zur Verfügung, der auf Basis einer Analyse der
Vorlieben des Users regelmäßig eine Empfehlung für neue WWW-
Seiten gibt. Je größer die Datenbasis über die individuellen
Präferenzen des Nutzers ist, desto treffender sind die Vorschläge
von Webhound. Dabei wird eine Methode namens »Feature-Guided Automated
Collaborative Filtering« angewendet, die die Präferenzen des Nutzers
mit denen anderer User vergleicht und bei einer Übereinstimmung deren Empfehlungen
an den Nutzer von Webhound weitergibt. Das System läuft als Client-Server-Architektur
auf mehreren Rechnern im Internet und unterhält dort Datenbanken über
die registrierten User, die auf Webhound entweder mittels eines WWW-Interfaces
oder eines Webhound-Clients, der zusammen mit einem modifizierten XMosaic- 2.4-Browser
auf dem eigenen Rechner installiert wird, zugreifen können.
BargainFinder (http://bf.cstar.ac.com/bf/)
BargainFinder wurde im Rahmen einer unter dem Titel "Smart Store Virtual" von
der Arthur Andersen Consulting Group durchgeführten Studie erstellt und
ist in der momentanen Form in der Lage, zu einem beliebigen eingegebenen CD-Titel
das preisgünstigste Angebot bei den im Netz vertretenen Anbietern zu ermitteln.
(Dieser Abschnitt über Agenten stammt teilweise aus der Proseminar-Arbeit »WWW-Unterstützung durch intelligente Agenten« von Michael Rohs, TH-Darmstadt und aus dem Referat »Intelligente Software-Agenten in elektronischen Märkten« von Christof Abert, Uni-Frankfurt!)
3 Suchoperatoren und Suchmethoden
Die Suchdienste des WWW bieten immer mehr und immer fortschrittlichere Methoden und Operatoren zur besseren und exakteren Suche an. Die verschiedenen Möglichkeiten sind meist bei den Hilfe-Funktionen der einzelnen Suchdienste ausführlich und mit Beispielen beschrieben. Nachfolgend werden Methoden und Operatoren erläutert, wie sie bei den meisten Suchdiensten in der einen oder anderen Weise, anwendbar sind.
Einige Suchdienste bieten verschiedene Suchmodi an. Mit einfacher Suche (Simple Search) wird dabei eine triviale Stichwortsuche bezeichnet, die mögliche Angabe zusätzlicher Kriterien und Operatoren als erweiterte Suche (Extended oder Power Search).
Bsp.: Simple Search
|
Alta Vista |
|
Bsp: Extended Search
|
Yahoo! |
|
Bei den meisten Diensten wird Groß-/Kleinschreibung nicht beachtet. Bei einigen Suchdiensten kann man die Unterscheidung bei Groß-/Kleinschreibung einstellen. Zum Beispiel wird nach Auftreten eines Großbuchstabens in der Suchanfrage die Schreibweise automatisch beachtet oder man muß das Wort in Hochkomma setzen.
|
Ultraseek |
|
Mit Trunkierung bezeichnet man die Suche nach verschieden Wortvariationen. Meist ist wahlweise eine echte Teilwortsuche oder exakte Suche des Suchbegriffs einstellbar. Bessere Suchdienste erlauben auch die Benutzung des sogenannten *-Operators, sogar an mehreren Positionen eines Suchwortes.
Bsp:
"hand*" - sucht nach allen Worten, die mit "hand" anfangen: Hand, Handschuh,
Handlung...
"ha*nd" - sucht nach allen Worten, die mit "ha" anfangen und mit "nd"
enden: Haushund, halbrund, Hainbund...
"*hand" - sucht nach allen Worten, die mit "hand" enden: Treuhand...
Einige Dienste bieten auch Gewichtung der Suchbegriffe an. Stärker gewichtete Suchbegriffe werden dann bei der Suche bevorzugt. Dabei variiert die Art der Angabe nach Häufigkeit des Auftretens eines Begriffs in der Suchanfrage bis zur Angabe eines Gewichtungsgrades.
Bsp.: Vergleich der
Suche nach »hypertext einfuehrung« und »hypertext hypertext
hypertext einfuehrung« :
|
Excite |
|
AND, OR, NOT (auch AND NOT),
bei manchen Diensten auch mit &, |, ! bzw. +, -, ~ geschrieben.
Mit AND verknüpfte Begriffe einer Suchanfrage liefern nur diejenigen Dokumente,
in denen alle verknüpften Begriffe vorkommen.
Bei der OR-Verknüpfung werden alle Dokumente geliefert, die mindestens
einen der verknüpften Begriffe beinhalten.
Mit NOT können Begriffe ausgeschlossen werden, d.h. Dokumente mit den NOT
verknüpften Begriffen werden nicht angezeigt.
Die Anwendung Boolescher Operatoren ist von Dienst zu Dienst unterschiedlich,
manche erlauben diese sogar mit Klammerung, andere aber nicht einmal Mischung
der verschiedenen Operatoren.
Bsp.: Boolesche Operatoren
beliebig anwendbar:
|
HotBot |
|
Bsp.: Boolesche Operatoren
nur beschränkt anwendbar (siehe "Art":)
3.6 Phrasensuche und Abstandsoperatoren
Mit der Phrasensuche (auch
ADJ-Operator) bezeichnet man die Suche nach der exakten Reihenfolge der angegebenen
Suchbegriffe. Um eine Phrasensuche einzuleiten, müssen die Suchbegriffe
meist in Hochkomma eingeschlossen sein.
Abstandsoperatoren, auch Proximity-Operatoren genannt, werden in diversen Formen
unterstützt. Mit dem NEAR- oder FOLLOWED-BY-Operator werden die Suchbegriffe
meist im Umkreis von 10 bis 100 Worten gesucht. Bei manchen Diensten kann man
auch angeben, wie nahe (Anzahl Worte) die Suchbegriffe im Text auftreten müssen.
Bsp.: Vergleich der
Suche nach »Bayern München« und der Phrasensuche nach
»"Bayern München"«:
|
flipper |
|
Bsp.: Begriffe »hypertext«
und »informationswissenschaft« in einer 20 Worte-Nähe
|
WebCrawler |
|
Es werden von einigen Diensten verschiedene Eingrenzungen des Suchraums angeboten. Dabei kann der Suchraum auf verschiedene Bereiche eingegrenzt werden:
Bsp: Advanced Search
von AltaVista
|
Alta Vista |
|
Suchraumeingrenzung über »Constraining searches« :It is possible to restrict searches to certain portions of documents by using the following syntax. The keyword (link, title, image,...) should be in lower-case, and immediately followed by a colon. Constraining searches in Web pages:
Constraining searches in Usenet news articles:
|
|
Bsp.:
|
HotBot |
|
||||||||||||||||||||||||||
Suchraumeingrenzung über »Meta Words« :These special search words can be added to queries to restrict search results in a number of ways. Most of these effects can also be achieved by using the controls on the HotBot page.
|
|||||||||||||||||||||||||||
Die meisten Dienste bieten eine Eingrenzung durch Angabe einer Trefferanzahl pro Ergebnisseite an. Blätterfunktionen am Ende einer Ergebnisseite ermöglichen das Navigieren zu den anderen Trefferseiten.
Alle Suchdienste berechnen Relevanzgrade, nach denen die Ergebnismenge sortiert ist. Die Berechnung basiert dabei meist auf statistischen Verfahren, d.h. Worthäufigkeit, Wortabstände usw.
Die Treffer werden in Form
einer nach Relevanz sortierten Verweis-Liste angezeigt (Ranking). Bei jedem
Suchdienst werden zumindest URL`s und Dokumenttitel angezeigt. Die meisten Dienste
präsentieren zusätzlich Ausschnitte, Kommentare oder Zusammenfassungen
aus den Originaldokumenten sowie zusätzliche Angaben wie Erstellungsdatum,
Größe usw. Meistens ist die Ausführlichkeit der Ergebnismenge
stufenweise einstellbar. Das Ranking ist teilweise auch farbig oder graphisch
aufbereitet.
Kataloge zeigen bei der Stichwortsuche auch die Katalog-Hierarchie der einzelnen
Treffer an.
Bsp.: siehe Trefferanzeige
nach folgender Suche:
|
Yahoo! |
|
3.11 Treffer-Weiterverarbeitung
Im Gegensatz zu den Hosts
der Online-Datenbanken ist die direkte Weiterverarbeitung einer Treffermenge
auf Seite des Suchservers nicht möglich. Dies liegt daran, daß HTTP
ein ,,zustandsloses" Protokoll ist, d.h. daß ein Server einen HTTP-Request
in einem Ablauf abarbeitet und nach dem Verbindungsabbau keine Möglichkeit
mehr bietet, auf diese Interaktion zurückzugreifen.
Trotzdem kann bei einigen Diensten eine Art Weiterverarbeitung bei einzelnen
Treffern genutzt werden. Diese erlauben die weitere Suche nach ähnlichen
Dokumenten eines Treffers oder die Anzeige aller Zeilen/Abschnitte eines Originaldokuments,
in denen der Suchbegriff vorkommt.
Bsp: Suchabfrage
starten und den Link »[More Like This]« bei einem interessanten
Treffer verfolgen
|
Excite |
|
4 Vorgehensweise bei der Suche
4.1 Ermittlung des Informationsbedürfnisses
Jede erfolgreiche Informationsrecherche im Internet erfordert eine gewisse Vorbereitung. Je mehr Aufmerksamkeit dieser Vorbereitung gewidmet wird, desto weniger Zeit braucht man bei der eigentlichen Suche.
4.2 Auswahl der richtigen Suchbegriffe
Bei der Suche über Stichworte, also hauptsächlich bei Suchmaschinen und speziellen Datenbanken, ist die geeignete Auswahl der Suchbegriffe entscheidend.
4.3
Auswahl geeigneter Suchverfahren
|
|
Suchverfahren |
|
Allgemeines Interesse und Neugier. Überraschung und Zufall stehen im Vordergrund. |
Spezielle Seiten mit interessanten Links zu aktuellen und populären Web-Seiten (Top 100, Cool Links, Wohin heute?, Top.deusw.) sind vor allem bei den Suchdiensten zu finden. |
|
Ein erster Überblick über ein bestimmtes Thema. Man weiß nicht ganz genau, wonach bzw. mit welchen Begriffen man suchen soll (»anomalous state of knowledge«). |
Internationale Kataloge und Deutschsprachige Kataloge 2. FAQ-Listen / Posting-Archive und Spezielle Home-Pages zu dem bestimmten Thema (z.B. Java-Dienste, Software-Kataloge) 3. Sonstige Übersichten, z.B. : Internationale Server-Listen/-Karten und Deutsche Server-Listen/-Karten 4. (Hybride) Suchmaschinen: Internationale Suchroboter und Deutschsprachige Suchroboter |
|
Ein konkretes Informationsproblem liegt vor. Man kennt die Suchbegriffe und es wird eine präzise Antwort erwartet. |
Internationale Suchroboter und Deutschsprachige Suchroboter 2. Metasuchmaschinen 3. Spezielle Kataloge, z.B.: E-Mail Adressensuche Internationale Yellow Pages und Deutschsprachige Gelbe Seiten Software-Kataloge und Java-Dienste Sonstige Suchmöglichkeiten 4. Spezielle Home-Pages zu einem bestimmten Thema und, falls möglich, eine lokale Suche in diesen. 5. Gateways zu speziellen Datenbanken (Online-Markt) (z.B. bei FIZ-Karlsruhe) |
|
Man möchte laufend über ein Thema informiert werden, z.B. Nachrichten über eine Firma, Aktienkurse, Wetter usw. |
Einschlägige Newsgroups lesen. Eintragen in Mailinglisten (Über WWW Listen finden und dann per E-Mail anmelden) bzw. Teilnahme an Diskussions-Foren Überwachung bestimmter Seiten über Überwachungsdienste (http://www.netmind.com/), d.h. bei jeder Änderung der Seite bekommt man eine E-Mail. Einige WWW-Dienste ermöglichen Anmeldungen über Formulare, um laufend über ein Thema informiert zu werden Elektronische Journale / E-Zines |
4.4 Durchführung der Recherche und Relevanzbeurteilung
Damit bei der Durchführung der Recherche die oben genannten Vorbereitungen gezielt umgesetzt werden können, sollten noch einige Punkte beachtet werden:
Die Treffer der jeweiligen Suchdienste sollten zur Relevanzbeurteilung in möglichst aussagekräftiger Form angezeigt und schon vor dem Laden der Treffer analysiert werden:
Als relevant eingestufte Treffer sollten sofort als Bookmark markiert werden, am besten in einem speziellen Such-Folder. Bei stark temporären WWW-Seiten, z.B. Zeitungsartikel usw., sollten die Trefferdokumente gleich auf die eigene Festplatte gespeichert werden, da diese oft nur ein paar Tage im WWW gehalten werden.
